Кустарная аудиокнига
Предисловие
Люблю книги. Но в плотном распорядке дня совсем нет времени на чтение. Спасение — аудиокниги. За неполный прошлый год удалось послушать 68 штук. А ещё люблю не просто книги, а серии — с большими мирами и раскрытыми персонажами.
На прошлой неделе закончила слушать очередную книгу из детективной серии и с ужасом обнаружила: следующие несколько книг не озвучены! Хотя пара последних в серии есть в аудиоверсии. Вот так просто, волей странных обстоятельств, нет центральной части истории.
Идея создавать свои аудиоверсии приходила и раньше, когда попадались неозвученные тайтлы. Но в этот раз проблема стояла остро и это сподвигло на действия.
Что понадобится
- Электронная книга в формате epub (или txt)
- Python 3+
- ffmpeg
- Calibre CLI
- npx (устанавливается вместе с Node.js) (если у вас его ещё нет)
- Учётная запись в Google Cloud с включённым биллингом
- Включённый Cloud Text-to-Speech API
Cook book
Подготовка текста
Первая мысль — просто скормить epub в какой-нибудь сервис и получить готовое аудио. Но все существующие продукты либо не заточены под большой объём текста, либо стоят дорого.
Ну что, разве я не разработчик? Пойдём разбираться.
Первым делом нужно преобразовать epub в обычный текст. Если уже есть чистый txt — этот шаг можно пропустить.
Для конвертации подойдёт Calibre CLI:
ebook-convert book.epub book.txtТак мы получаем файл book.txt с полным текстом книги.
После этого откройте book.txt и удалите всё лишнее: оглавление, предисловие, послесловие, примечания и т.д. Нам нужен только основной текст книги. Всё, что будет в этом файле — будет озвучено. Лишнее слушать нудно и это тратит драгоценные токены.
Нарезка на главы
Дальше я нарезала книгу на главы. Во-первых, я не знала, каким будет результат и было бы обидно озвучить всю книгу, а потом понять, что мне не нравится. Лучше разочароваться пораньше. Во-вторых, я не была уверена, как будет тарифицироваться генерация речи и решила озучивать по одной главе, чтобы следить за затратами и не обалдеть от суммы в конце. Спойлер: вышло бесплатно.
Книгу я резала по главам с небольшими условиями. Всё, что до первой главы — предисловие. В начале каждого файла главы должно быть «Глава №», чтобы голос это проговаривал.
Заодно немного нормализовала текст. Почистила лишние переносы строк, пробелы, чтобы в озвучке не было пауз.
Использовала Python-скрипт:
Скрипт нарезки на главы
#!/usr/bin/env python3
from __future__ import annotations
from dataclasses import dataclass
from pathlib import Path
import json
import re
from typing import List, Optional
INPUT = "book.txt" # входной файл с текстом книги
OUT_DIR = Path("chapters")
OUT_DIR.mkdir(exist_ok=True)
# Ищем явные главы/части. "Пролог" вытащим отдельной логикой.
CHAPTER_RE = re.compile(r"(?im)^\s*(глава|часть)\s+([0-9]+|[ivxlcdm]+)\b.*$")
# Явный заголовок пролога (если есть строкой)
PROLOG_RE = re.compile(r"(?im)^\s*пролог\b.*$")
# Если глав нет — режем на части фикс. размера
FALLBACK_PART_CHARS = 120_000
@dataclass
class Section:
index: int
title: str # для человека
heading: str # что будет озвучено в начале файла
text: str
def safe_slug(s: str, max_len: int = 60) -> str:
s = s.strip().lower()
s = re.sub(r"[^\wа-яё]+", "_", s, flags=re.IGNORECASE)
s = s.strip("_")
return (s[:max_len] if s else "section")
def normalize_preserve_paragraphs(t: str) -> str:
t = t.replace("\ufeff", "")
t = t.replace("\r\n", "\n").replace("\r", "\n")
# Схлопываем слишком много пустых строк
t = re.sub(r"\n{3,}", "\n\n", t)
# Пробелы/табы внутри строк — да, но НЕ переносы строк
t = re.sub(r"[ \t]+", " ", t)
return t.strip()
def add_paragraph_pauses(t: str) -> str:
"""
Делает паузы на абзацах:
Двойной перенос -> '.\n\n' (если перед ним не было знака конца предложения).
"""
# сначала нормализуем разные варианты "пустой строки"
t = re.sub(r"\n\s*\n", "\n\n", t)
# добавим точку перед абзацем, если её нет
t = re.sub(r"(?<![.!?…])\n\n", ".\n\n", t)
return t
def split_by_markers(lines: List[str], markers: List[int]) -> List[tuple[str, str]]:
# возвращает список (title_line, body_text)
out = []
for k, start in enumerate(markers):
end = markers[k + 1] if k + 1 < len(markers) else len(lines)
title = lines[start].strip()
body = "\n".join(lines[start + 1:end]).strip()
if body:
out.append((title, body))
return out
def split_into_sections(text: str) -> List[Section]:
lines = text.split("\n")
# 1) находим главы/части
chapter_markers = [i for i, line in enumerate(lines) if CHAPTER_RE.match(line.strip())]
# 2) если глав не нашли — fallback
if not chapter_markers:
sections: List[Section] = []
raw = text
start = 0
idx = 1
while start < len(raw):
part = raw[start:start + FALLBACK_PART_CHARS].strip()
if part:
sections.append(Section(index=idx, title=f"Part {idx}", heading=f"Часть {idx}.", text=part))
idx += 1
start += FALLBACK_PART_CHARS
return sections
sections: List[Section] = []
# 3) ПРОЛОГ: всё до первой главы
first_marker = chapter_markers[0]
before = "\n".join(lines[:first_marker]).strip()
# Если в этом куске есть явное слово "Пролог" строкой — считаем, что это пролог.
if before:
sections.append(
Section(
index=1,
title="Пролог",
heading="Пролог.",
text=before
)
)
# 4) ГЛАВЫ
chapters = split_by_markers(lines, chapter_markers)
chapter_num = 1
for title, body in chapters:
sections.append(
Section(
index=len(sections) + 1,
title=title,
heading=f"Глава {chapter_num}.",
text=body
)
)
chapter_num += 1
return sections
def main():
raw = Path(INPUT).read_text(encoding="utf-8", errors="ignore")
raw = normalize_preserve_paragraphs(raw)
raw = add_paragraph_pauses(raw)
sections = split_into_sections(raw)
print(f"Sections: {len(sections)}")
manifest = {
"input": INPUT,
"sections_dir": str(OUT_DIR),
"sections": [],
"total_chars": 0,
"total_utf8_bytes": 0,
"note": "Per-section counts include spoken heading and inserted paragraph pauses.",
}
for s in sections:
fname = f"{s.index:03d}_{safe_slug(s.title)}.txt"
path = OUT_DIR / fname
full_text = f"{s.heading}\n\n{s.text}".strip()
path.write_text(full_text, encoding="utf-8")
chars = len(full_text)
utf8_bytes = len(full_text.encode("utf-8"))
manifest["sections"].append({
"index": s.index,
"title": s.title,
"heading": s.heading,
"file": str(path),
"chars": chars,
"utf8_bytes": utf8_bytes,
})
manifest["total_chars"] += chars
manifest["total_utf8_bytes"] += utf8_bytes
print(f"[{s.index:03d}] {s.heading} -> {fname} | chars={chars} | bytes={utf8_bytes}")
(OUT_DIR / "manifest.json").write_text(
json.dumps(manifest, ensure_ascii=False, indent=2),
encoding="utf-8"
)
print("\nTotals:")
print(f" total chars: {manifest['total_chars']}")
print(f" total utf-8 bytes: {manifest['total_utf8_bytes']}")
print(f"Manifest: {OUT_DIR / 'manifest.json'}")
if __name__ == "__main__":
main()В итоге получаем папку chapters/ с файлами глав и манифестом manifest.json, в котором есть информация по всем главам: сколько символов, байт и т.д.
Добавление Ё
После первых попыток озвучки стало понятно: текст без Ё звучит плохо. Поэтому добавился шаг с автоматической расстановкой Ё через библиотеку eyo-kernel.
npx eyo chapters/002_глава_1.txt > chapters/002_глава_1.yo.txtТеперь текст готов к озвучке.
Проблемы инструментов
Конечно, хотелось сделать это за 0 денег. Первым делом — поиск опенсорсных TTS-движков.
Попробовала Silero TTS. Спасибо мейнтейнерам проекта! Но качество не подошло. С чтением всё было ок, но на стыках между фразами голос плыл. Кто ещё застал аудиокассеты — точно помнит этот звук, когда в плеере садились батарейки. Примерно так звучали эти стыки.
Вздохнула и пошла искать платные, но недорогие решения.
Google Cloud Text-to-Speech
Сервисов много, но выбор пал на Google Cloud Text-to-Speech — там, как оказалось, висел неиспользованный кредит.
Для работы с сервисом нужно создать аккаунт, привязать биллинг и включить API Cloud Text-to-Speech.
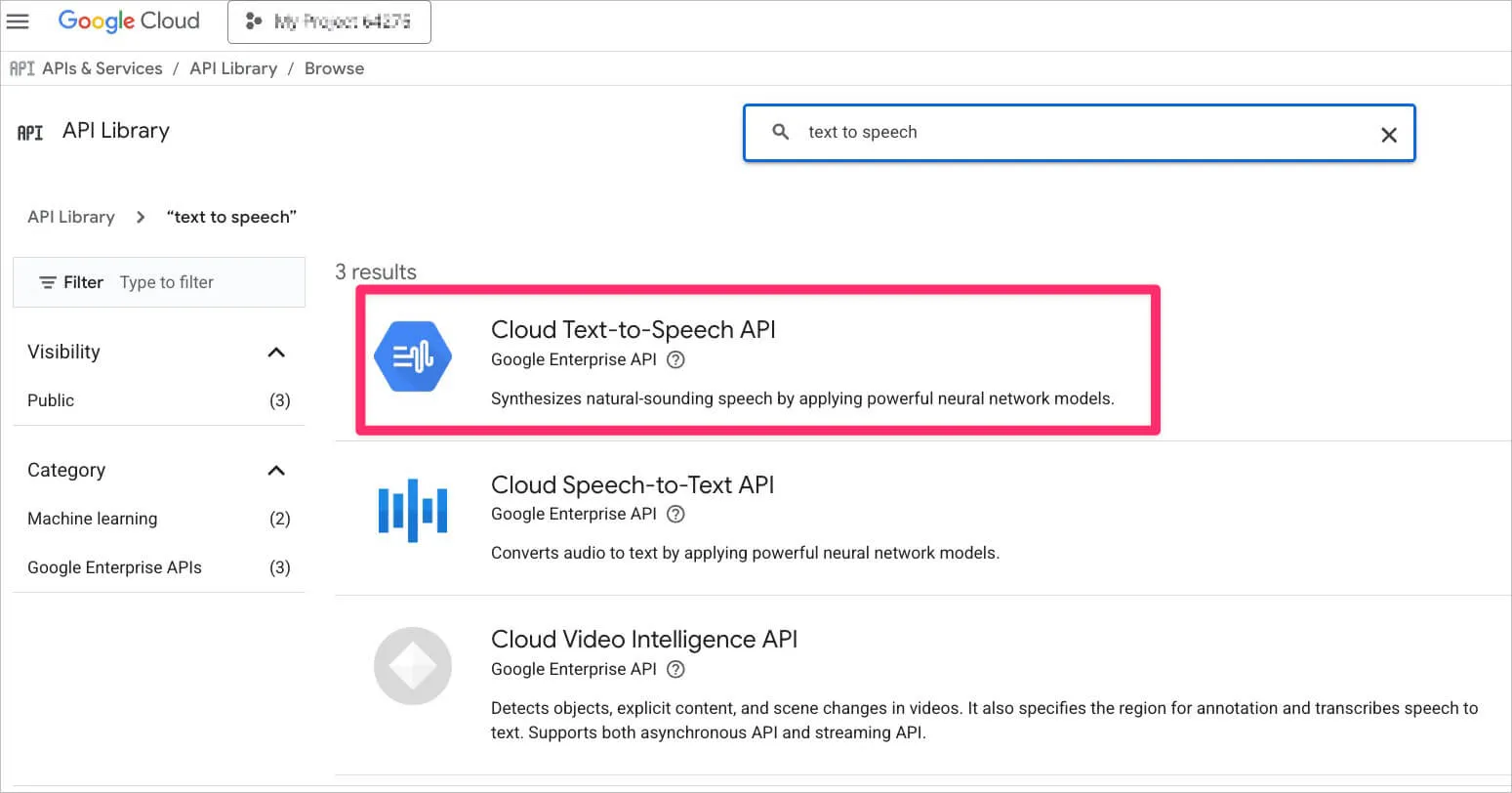
Обязательно изучите прайс. Есть голоса по $100+ за миллион символов. Студийное качество на этом этапе не нужно, поэтому выбор — недорогие голоса WaveNet. Послушать семплы. Понравился ru-RU-Wavenet-D (~$4 за миллион символов).
Авторизация в gcloud CLI:
gcloud auth application-default loginИ поехали озвучивать.
Скрипт озвучки
Что важно в скрипте озвучки:
- Разбивка текста на куски по 5000 байт (ограничение API). Важно: именно байт, не символов! Кириллица в UTF-8 занимает 2 байта на символ, реальный лимит ~2400-2500 символов. Для подстраховки —
MAX_BYTES_DEFAULT = 4800. - Резать текст по предложениям (
[.!?…]), не в случайных местах. Слишком длинные предложения — по пробелам. - Озвученные чанки сохранять во временную папку
tmp_audio_run/, чистить её перед озвучкой каждой главы. - Склейка чанков через ffmpeg — быстро и без потери качества.
- В конце вывод количества символов и байтов для оценки стоимости.
На выходе — mp3.
Скрипт озвучки через Google TTS
#!/usr/bin/env python3
from __future__ import annotations
from pathlib import Path
import argparse
import subprocess
import re
import shutil
from google.cloud import texttospeech
# ====== Google TTS settings (defaults) ======
LANG_DEFAULT = "ru-RU"
VOICE_DEFAULT = "ru-RU-Wavenet-D"
RATE_DEFAULT = 0.95
# Google limit is 5000 BYTES per request; keep margin.
MAX_BYTES_DEFAULT = 4800
SENT_CUT_RE = re.compile(r"([.!?…]+)\s+")
def split_sentences(t: str):
parts = SENT_CUT_RE.split(t)
out = []
for i in range(0, len(parts), 2):
chunk = parts[i].strip()
punct = parts[i + 1] if i + 1 < len(parts) else ""
s = (chunk + punct).strip()
if s:
out.append(s)
return out
def chunk_by_utf8_bytes(text: str, max_bytes: int):
sentences = split_sentences(" ".join(text.split()))
chunks = []
cur = ""
def fits(s: str) -> bool:
return len(s.encode("utf-8")) <= max_bytes
for s in sentences:
if not s:
continue
candidate = (cur + " " + s).strip() if cur else s
if fits(candidate):
cur = candidate
continue
if cur:
chunks.append(cur)
cur = ""
# single sentence too long -> split by words
if not fits(s):
words = s.split()
tmp = ""
for w in words:
cand = (tmp + " " + w).strip() if tmp else w
if fits(cand):
tmp = cand
else:
if tmp:
chunks.append(tmp)
tmp = w
if tmp:
chunks.append(tmp)
else:
cur = s
if cur:
chunks.append(cur)
return chunks
def ffmpeg_concat_mp3(tmp_dir: Path, output_mp3: Path):
subprocess.run(
["ffmpeg", "-y", "-f", "concat", "-safe", "0", "-i", "files.txt", "-c", "copy", "out.mp3"],
check=True,
cwd=str(tmp_dir),
)
output_mp3.parent.mkdir(parents=True, exist_ok=True)
(tmp_dir / "out.mp3").replace(output_mp3)
def main():
ap = argparse.ArgumentParser(
description="Generate MP3 from a text file using Google Cloud TTS (WaveNet) with safe UTF-8 byte chunking."
)
ap.add_argument("input", help="Path to input .txt file")
ap.add_argument("-o", "--output", help="Output .mp3 path (default: рядом с входным файлом)")
ap.add_argument("--voice", default=VOICE_DEFAULT, help=f"Voice name (default: {VOICE_DEFAULT})")
ap.add_argument("--lang", default=LANG_DEFAULT, help=f"Language code (default: {LANG_DEFAULT})")
ap.add_argument("--rate", type=float, default=RATE_DEFAULT, help=f"Speaking rate (default: {RATE_DEFAULT})")
ap.add_argument("--max-bytes", type=int, default=MAX_BYTES_DEFAULT, help=f"Max UTF-8 bytes per request (default: {MAX_BYTES_DEFAULT})")
ap.add_argument("--tmp-dir", default="tmp_audio_run", help="Temporary directory for mp3 chunks (default: tmp_audio_run)")
ap.add_argument("--clean", action="store_true", help="Delete temp directory before run")
args = ap.parse_args()
input_path = Path(args.input)
if not input_path.exists():
raise SystemExit(f"Input not found: {input_path}")
out_path = Path(args.output) if args.output else input_path.with_suffix(".mp3")
tmp_dir = Path(args.tmp_dir)
if args.clean and tmp_dir.exists():
shutil.rmtree(tmp_dir)
tmp_dir.mkdir(parents=True, exist_ok=True)
text = input_path.read_text(encoding="utf-8", errors="ignore").strip()
if not text:
raise SystemExit("Input file is empty.")
parts = chunk_by_utf8_bytes(text, args.max_bytes)
if not parts:
raise SystemExit("No chunks produced (unexpected).")
client = texttospeech.TextToSpeechClient()
voice = texttospeech.VoiceSelectionParams(language_code=args.lang, name=args.voice)
audio_cfg = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
speaking_rate=args.rate,
)
filelist = []
total_chars = 0
total_utf8_bytes = 0
for i, part in enumerate(parts, 1):
b = len(part.encode("utf-8"))
if b > args.max_bytes:
raise SystemExit(f"Chunk {i} too big: {b} bytes (max {args.max_bytes})")
total_utf8_bytes += b
total_chars += len(part)
resp = client.synthesize_speech(
input=texttospeech.SynthesisInput(text=part),
voice=voice,
audio_config=audio_cfg,
)
fname = tmp_dir / f"part_{i:04d}.mp3"
fname.write_bytes(resp.audio_content)
filelist.append(fname)
if i % 25 == 0 or i == len(parts):
print(f"Parts: {i}/{len(parts)}")
(tmp_dir / "files.txt").write_text(
"\n".join(f"file '{f.name}'" for f in filelist),
encoding="utf-8"
)
ffmpeg_concat_mp3(tmp_dir, out_path)
print(f"Done: {out_path}")
print(f"Chunks: {len(parts)}")
print(f"Total chars sent: {total_chars}")
print(f"Total utf-8 bytes sent: {total_utf8_bytes}")
if __name__ == "__main__":
main()Озвучка глав
Запуск скрипта для каждой главы:
python gcloud_tts_file.py chapters/001_prolog.txt -o audio/001_prolog.mp3 --cleanФлаги:
--clean— очистка временной папки перед запуском;-o— путь к выходному mp3.
В скрипте есть и другие флаги — настраивайте под себя.
Результат — аудиофайл для каждой главы.
Profit!
Отлично провела время, разбираясь во всём этом. И в итоге послушала книгу =)
Цена
Книга обошлась бесплатно: не превысила 1 миллион символов, уместилась в бесплатный лимит WaveNet.
Зоны развития
Робот-диктор
Стоит быть готовым: это не живой диктор. В озвучке будет много неправильных ударений, произношений, интонаций.
Чтобы оценить уровень — короткий семпл:
Для художественной литературы такой вариант лично мне не подошёл. В итоге перешла на аудиокниги на английском. Тут вспоминается поговорка про два стула: либо робот-диктор на русском, либо великолепный диктор на английском.
А вот для технической литературы, которая не озвучена это отличный подход.
Разметка текста
В идеале отдавать на озвучку не txt, а SSML — для управления паузами, ударениями, скоростью. Но это следующий уровень. В этот раз не было времени и желания уходить глубже.
Интерфейс
Пока все команды запускаются руками в терминале. На начальном этапе это ок для отладки. Когда флоу устаканится соберу в один интерфейс: окно, куда кидаешь файл с книгой, а на выходе плеер с аудио.
Один файл
В этот раз работала с каждой главой отдельно и это было обосновано. В следующий раз автоматизирую все промежуточные шаги. В конце буду склеивать всё в один m4b файл с главами и обложкой.